APIs Sources
A few data sources were identified to supply the Data Pipeline and be used as main data for this project:
- Moby Bikes has a public API where it provides current locations of the bikes in operation in the Dublin area and is updated every 5 minutes. There are also rollups of historic bike location data (30 minutes granularity) available as downloadable CSV resources.
- The Met Éireann WDB API outputs a detailed point forecast in XML format for a coordinate point as defined by the user.
- Calendarific Global Holidays API is a RESTful API giving you access to public, local & bank holidays and observances. An API key is required for every request to the Holiday API.
The Data Pipeline was built on AWS Services, as demonstrated in the diagram below:
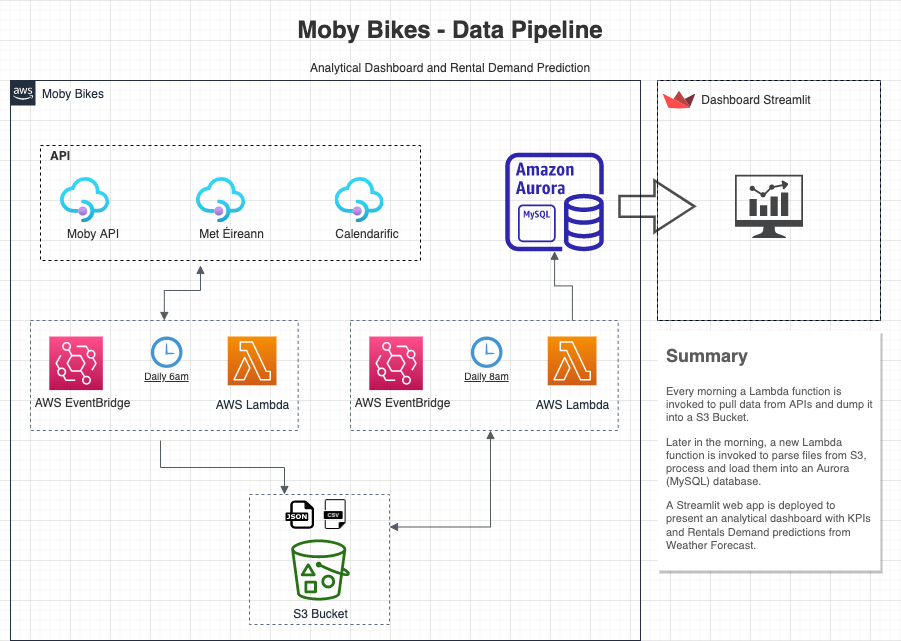
Description
Lambda Function - PullAPIDataMobyBikes
A trigger event was created to run every morning at 6am which will pull data from APIs and dump it into a S3 Bucker.
import pandas as pd
from datetime import datetime, timedelta
import os
import requests
import json
import boto3
s3_client = boto3.client("s3")
LOCAL_FILE_SYS = "/tmp"
S3_BUCKET = "moby-bikes-rentals"
today_dt = datetime.now()
today_dt_str = today_dt.strftime("%Y-%m-%d")
yesterday_dt = today_dt - timedelta(days=1)
yesterday_dt_str = yesterday_dt.strftime("%Y-%m-%d")
###############################################################
# Dublin Airport Yesterday Data
# https://data.gov.ie/dataset/yesterdays-weather-dublin-airport
###############################################################
# Download CSV
# URL: https://www.met.ie/latest-reports/observations/download/Dublin-Airport/yesterday
# API (sometimes is not working) - 504 Gateway Timeout
# Checking alternative with CSV file
# URL: https://prodapi.metweb.ie/observations/dublin/yesterday
def format_hour(hour) -> int:
'''
Receives a string of the form 'HH:MM' and returns a integer with the hour
'''
hour_str = hour.split(':')
return int(hour_str[0])
def key_exists(mykey, mybucket):
if result := s3_client.list_objects_v2(Bucket=mybucket, Prefix=mykey):
return 'Contents' in result
headers={'content-type': 'application/json', 'accept': 'application/json'}
WEATHER_DATA_API_URL = "https://prodapi.metweb.ie/observations/dublin/yesterday"
WEATHER_DATA_CSV_URL = 'https://www.met.ie/latest-reports/observations/download/Dublin-Airport/yesterday'
# ROOT_DIR_LOCAL = os.path.abspath(os.curdir)
def get_weather_data():
try:
api_response = requests.get(WEATHER_DATA_API_URL, headers=headers)
json_str = api_response.text
parse_json = json.loads(json_str)
if api_response:
weather_filename = f'{yesterday_dt_str}.json'
else:
weather_filename = f'{yesterday_dt_str}_error.json'
with open(LOCAL_FILE_SYS + "/" + weather_filename, 'w', encoding='utf-8') as f:
json.dump(parse_json, f, ensure_ascii=False, indent=4)
except Exception:
try:
dubairport_yesterday = pd.read_csv(WEATHER_DATA_CSV_URL)
dubairport_yesterday.columns = ['time', 'report', 'temp', 'wdsp', 'wind_gust', 'wind_direction', 'rain', 'pressure']
dubairport_yesterday['time'] = dubairport_yesterday['time'].apply(format_hour)
dubairport_yesterday.drop(['report', 'wind_gust', 'wind_direction', 'pressure'], axis=1, inplace=True)
weather_filename = f'{yesterday_dt_str}.csv'
dubairport_yesterday.to_csv(LOCAL_FILE_SYS + "/" + weather_filename, index=False)
except Exception as e:
weather_filename = f'{yesterday_dt_str}_error.txt'
with open(LOCAL_FILE_SYS + "/" + weather_filename, 'w') as f:
f.write(e.__str__())
finally:
if key_exists("weather_" + weather_filename, S3_BUCKET):
print("Weather data file already in S3 bucket!")
else:
s3_client.upload_file(LOCAL_FILE_SYS + "/" + weather_filename, S3_BUCKET, "weather_" + weather_filename)
def get_rentals_data():
###############################################################
# Moby Bikes Data
# https://data.gov.ie/dataset/moby-bikes
###############################################################
# Moby API
# URL: https://data.smartdublin.ie/mobybikes-api/
#parameters = None
parameters = {
"start": yesterday_dt_str,
"end": today_dt_str
}
baseurl = "https://data.smartdublin.ie/mobybikes-api/"
# last_reading_url = f'{baseurl}last_reading/'
historical_url = f'{baseurl}historical/'
api_response_moby = requests.get(historical_url, headers=headers, params=parameters)
moby_json_str = api_response_moby.text
moby_parse_json = json.loads(moby_json_str)
if api_response_moby:
moby_json_filename = f'{yesterday_dt_str}.json'
else:
moby_json_filename = f'{yesterday_dt_str}_error.json'
with open(LOCAL_FILE_SYS + "/" + moby_json_filename, 'w', encoding='utf-8') as f:
json.dump(moby_parse_json, f, ensure_ascii=False, indent=4)
if key_exists("moby_" + moby_json_filename, S3_BUCKET):
print("Moby rentals data file already in S3 bucket!")
else:
s3_client.upload_file(LOCAL_FILE_SYS + "/" + moby_json_filename, S3_BUCKET, "moby_" + moby_json_filename)
def lambda_handler(event, context):
'''
Loads the weather data from the API and saves it to S3
'''
get_weather_data()
get_rentals_data()
Lambda Function - Persist-Data-From-S3-To-Aurora-Mysql
A trigger event later in the morning (at 8am) was created to parse those files created from the lambda above and store them into an Aurora (MySQL) database.
import json
from datetime import datetime
import mysql.connector
from mysql_conn import mysqldb as mysqlcredentials
import boto3
import numpy as np
s3_client = boto3.client("s3")
S3_BUCKET = "moby-bikes-rentals"
def openDB_connection():
conn = mysql.connector.connect(**mysqlcredentials.config)
cursor = conn.cursor()
return conn, cursor
def get_file_tag(fileName):
# Example of tag 'TagSet': [{'Key': 'rental', 'Value': ''}]
# If object has no tagging, setting tag = None
try:
tag = s3_client.get_object_tagging(Bucket=S3_BUCKET, Key=fileName)['TagSet'][0]['Key']
except Exception:
tag = None
return tag
def remove_file_tag(fileName):
s3_client.delete_object_tagging(Bucket=S3_BUCKET,Key=fileName)
def add_file_tag(fileName, tag):
try:
today_dt = datetime.now()
today_dt_str = today_dt.strftime("%Y-%m-%d")
new_tag = {'TagSet': [{'Key': tag, 'Value': today_dt_str}]}
s3_client.put_object_tagging(Bucket=S3_BUCKET, Key=fileName, Tagging=new_tag)
return True
except Exception:
return False
def times_of_day(hour: int) -> str:
'''
Receives an hour and returns the time of day
Morning: 7:00 - 11:59
Afternoon: 12:01 - 17:59
Evening: 18:00 - 22:59
Night: 23:00 - 06:59
'''
conditions = [
(hour < 7), # night 23:00 - 06:59
(hour >= 7) & (hour < 12), # morning 7:00 - 11:59
(hour >= 12) & (hour < 18), # afternoon 12:01 - 17:59
(hour >= 18) & (hour < 23) # evening 18:00 - 22:59
]
values = ['Night', 'Morning', 'Afternoon', 'Evening']
return str(np.select(conditions, values,'Night'))
def rain_intensity_level(rain: float) -> str:
'''
Receives a rain intensity (in mm) and returns the rain intensity level
'''
conditions = [
(rain == 0.0), # no rain
(rain <= 0.3), # drizzle
(rain > 0.3) & (rain <= 0.5), # light rain
(rain > 0.5) & (rain <= 4), # moderate rain
(rain > 4) # heavy rain
]
values = ['no rain', 'drizzle', 'light rain', 'moderate rain','heavy rain']
return str(np.select(conditions, values))
def feat_eng_weather(data: list) -> list:
'''
Receives a List with tuples weather data from JSON file
and returns a new list with feature engineered data
0 - ['temperature'],
1 - ['windSpeed'],
2 - ['humidity'],
3 - ['rainfall'],
4 - ['date'],
5 - ['reportTime']
Returns:
(Date, Hour, TimeOfDay, Temperature, WindSpeed, Humidity, Rain, RainLevel)
'''
return [(convert_date(str.strip(i[4])),
str.strip(i[5].split(':')[0]),
times_of_day(int( str.strip(i[5].split(':')[0]) )),
force_integer( str.strip(i[0]) ),
force_integer( str.strip(i[1]) ),
force_integer( str.strip(i[2]) ),
str.strip(i[3]),
rain_intensity_level(float( str.strip(i[3]) ))) for i in data]
def convert_date(date_weather: str) -> str:
'''
Receives a date 'dd-mm-yyyy' and returns a date like 'yyyy-mm-dd'
'''
return datetime.strptime(date_weather, "%d-%m-%Y").strftime("%Y-%m-%d")
def get_date_from_filename(filename: str) -> str:
'''
Receives a filename and returns the date from the filename
'''
filename = filename.split('.')[0]
return filename.split('_')[1]
def force_integer(input_number):
try:
tmp = int(input_number)
except Exception:
tmp = 0
return tmp
def process_files_data(fileType='rentals') -> list:
if fileType == 'rentals':
filePrefix = 'moby_'
elif fileType == 'weather':
filePrefix = 'weather_'
files_in_bucket = s3_client.list_objects(Bucket=S3_BUCKET, Prefix=filePrefix)
all_data=[]
files_queued = []
if 'Contents' in files_in_bucket:
for v in files_in_bucket['Contents']:
tag = get_file_tag(v['Key'])
if not tag: # if object is not tagged, needs to be processed
files_queued.append(v['Key'])
obj = s3_client.get_object(Bucket=S3_BUCKET, Key=v['Key'])
json_data = json.loads(obj['Body'].read().decode('utf-8'))
if fileType == 'rentals':
list_rdata = [(i['LastRentalStart'],
i['BikeID'],
i['Battery'],
i['LastGPSTime'],
i['Latitude'],
i['Longitude']) for i in json_data]
all_data.extend(list_rdata)
elif fileType == 'weather':
list_wdata = [(i['temperature'],
i['windSpeed'],
i['humidity'],
i['rainfall'],
i['date'],
i['reportTime']) for i in json_data]
list_wdata = feat_eng_weather(list_wdata)
all_data.extend(list_wdata)
return all_data, files_queued
def lambda_handler(event, context):
conn, cursor = openDB_connection()
try:
rentals_data, rfiles_queued = process_files_data(fileType='rentals')
if rentals_data:
stmt = """INSERT IGNORE INTO mobybikes.rawRentals (LastRentalStart, BikeID, Battery, LastGPSTime, Latitude, Longitude) VALUES (%s, %s, %s, %s, %s, %s)"""
cursor.executemany(stmt,rentals_data)
if rfiles_queued:
for fileName in rfiles_queued:
add_file_tag(fileName,'processed')
None if conn.autocommit else conn.commit()
print(cursor.rowcount, "record(s) inserted.")
else:
print('No Rental files were found to be processed!')
except mysql.connector.Error as error:
print(f"Failed to update record to database rollback: {error}")
# reverting changes because of exception
conn.rollback()
if rfiles_queued:
for fileName in rfiles_queued:
add_file_tag(fileName,'error')
finally:
cursor.callproc('SP_RENTALS_PROCESSING')
None if conn.autocommit else conn.commit()
try:
weather_data, wfiles_queued = process_files_data(fileType='weather')
if weather_data:
stmt = """INSERT IGNORE INTO mobybikes.Weather (Date, Hour, TimeOfDay, Temperature, WindSpeed, Humidity, Rain, RainLevel) VALUES (%s, %s, %s, %s, %s, %s, %s, %s)"""
cursor.executemany(stmt,weather_data)
if wfiles_queued:
for fileName in wfiles_queued:
args = (get_date_from_filename(fileName),)
cursor.callproc('SP_LOG_WEATHER_EVENTS', args)
add_file_tag(fileName,'processed')
None if conn.autocommit else conn.commit()
else:
print('No Weather files were found to be processed!')
except mysql.connector.Error as error:
print(f"Failed to update record to database rollback: {error}")
# reverting changes because of exception
conn.rollback()
if wfiles_queued:
for fileName in wfiles_queued:
add_file_tag(fileName,'error')
# closing database connection.
cursor.close()
conn.close()
Streamlit dashboard
A Streamlit web app is deployed to present an analytical dashboard with KPIs and Rentals Demand predictions from Weather Forecast.
See dashboard mockup